KeyError: "There is no item named 'word/NULL' in the archive"
半年前写过一个小的 Python 脚本来帮助分析一些工作文档的内容,其中 .docx 文件是用 python-docx 来解析的,但今天碰到一个问题,直接在加载文件的时候就报错了,call stack 还涉及到了 zipfile 之类的,一看就不是善茬:
Traceback (most recent call last):
File "c:\util\doc_parser.py", line 157, in parse_spec_file
doc = Document(filepath)
File "c:\util\venv\lib\site-packages\docx\api.py", line 25, in Document
document_part = Package.open(docx).main_document_part
File "c:\util\venv\lib\site-packages\docx\opc\package.py", line 128, in open
pkg_reader = PackageReader.from_file(pkg_file)
File "c:\util\venv\lib\site-packages\docx\opc\pkgreader.py", line 35, in from_file
sparts = PackageReader._load_serialized_parts(
File "c:\util\venv\lib\site-packages\docx\opc\pkgreader.py", line 69, in _load_serialized_parts
for partname, blob, reltype, srels in part_walker:
File "c:\util\venv\lib\site-packages\docx\opc\pkgreader.py", line 110, in _walk_phys_parts
for partname, blob, reltype, srels in next_walker:
File "c:\util\venv\lib\site-packages\docx\opc\pkgreader.py", line 105, in _walk_phys_parts
blob = phys_reader.blob_for(partname)
File "c:\util\venv\lib\site-packages\docx\opc\phys_pkg.py", line 108, in blob_for
return self._zipf.read(pack_uri.membername)
File "C:\Users\xxx\AppData\Local\Programs\Python\Python38\lib\zipfile.py", line 1475, in read
with self.open(name, "r", pwd) as fp:
File "C:\Users\xxx\AppData\Local\Programs\Python\Python38\lib\zipfile.py", line 1514, in open
zinfo = self.getinfo(name)
File "C:\Users\xxx\AppData\Local\Programs\Python\Python38\lib\zipfile.py", line 1441, in getinfo
raise KeyError(
KeyError: "There is no item named 'word/NULL' in the archive"
在网上简单搜索了下,似乎没什么好用的招,也看到 CSDN 上有个曲线救国的方案,大致就是手工解压后,直接用 BeautifulSoup 对其中感兴趣的 xml 内容进行解析。
中间还尝试过将文件另存、将文件内容复制粘贴到另外一个新建的文件,结果都还是不行,感觉基本可以排除文件格式方面的影响了。
继续在网上搜索,看到 python-docx 官网上的这个帖子,有点意思:
The way I would fix it on a single file would be to extract the package using opc-diag, grep through the relationship files to find NULL with something like grep NULL *.rels, and then just delete the offending relationship line.
对于 .docx 文件,我除了知道它们其实都是压缩文件,也没有更多的了解了。。。但看了这段话,结合前面做过的实验,感觉应该还是文档的内容有问题,准备老老实实看下内容,很不幸这个文档还 300 多页。。。只好切换到打印预览模式下缩小了先大致看下,结果比较容易就看到问题了,有两张引用的图像不存在!在 Word 里直接把这两个坏引用删除掉,保存后再用脚本解析就没问题了!

后来还尝试着把文件用 7-Zip 打开,可以找到对应的问题点:
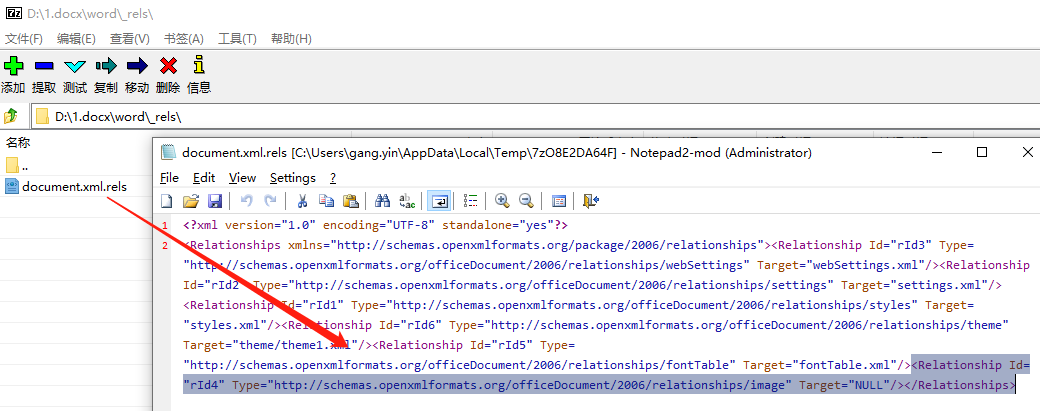
本来想提个 Issue,看到有现成的就直接回复了下,先看看官方对这类问题是否值得修复是什么态度吧:fix: accommodate NULL relationship (by skipping)。