第 20 章 效能設計
到目前為止,關於軟體設計的討論都集中在複雜性上。目標是使軟體儘可能簡單易懂。但是,如果你需要讓一個系統執行的更加高效,該怎麼辦?效能方面的考慮應如何影響設計過程?本章討論如何在不犧牲簡潔設計的情況下實現高效能。最重要的想法仍然是簡單性:簡單性不僅可以改善系統的設計,而且通常可以使系統更快。
20.1 如何考慮效能
要解決的第一個問題是:“在正常的開發過程中,你應該在多大程度上擔心效能?” 如果你嘗試最佳化每條語句以獲得最大速度,則它將減慢開發速度併產生很多不必要的複雜性。此外,許多“最佳化”實際上對效能沒有幫助。另一方面,如果你完全忽略了效能問題,則很容易導致整個程式碼中出現大量低效的設計實現,結果系統很容易比所需的速度慢 5–10 倍。在這種“木已成舟”的情況下,再想回來改進效能也很難了,因為沒有任何單一的改進會產生很大的影響。
最好的方法是介於這兩種極端之間,你可以利用效能相關的基本知識來選擇“自然高效”但又整潔和簡單的設計方案。關鍵是要意識到哪些操作從根本上來說是效能開銷大的。以下是一些今天仍然相對開銷大的操作示例:
- 網路通訊:即使在資料中心內,往返訊息交換也可能要花費 10 到 50 微秒,相當於數以萬計的指令的執行時間。而廣域網的訊息往返可能需要 10 到 100 毫秒。
- 輔助儲存的 I/O:磁碟的 I/O 操作通常需要 5 到 10 毫秒,這是數百萬條指令的執行時間。快閃記憶體儲存需要 10 到 100 微秒。新出現的非易失性儲存器的速度可能高達 1 微秒,但這仍然是大約 2000 條指令的執行時間。
- 動態記憶體分配(C 語言中的
malloc, C++ 或 Java 中的new)通常涉及分配、釋放和垃圾回收的大量開銷。 - 快取缺失:將資料從記憶體提取到處理器片上的快取記憶體中需要數百條指令的執行時間;在許多程式中,整體效能受快取缺失的影響程度與受計算開銷的影響程度一樣大。
瞭解哪些操作是效能開銷大的最好方法是執行微基準測試(單獨衡量單個操作成本的小程式)。在 RAMCloud 專案中,我們建立了一個提供微基準測試框架的簡單程式。建立該框架花了幾天時間,但是該框架使在五到十分鐘內新增新的微基準測試成為可能。這使我們積累了幾十個微基準測試。我們既可以使用它們來了解 RAMCloud 中使用的現有庫的效能,也可以衡量為 RAMCloud 編寫的新類的效能。
一旦你對什麼是效能開銷大的和什麼是效能開銷小的有了大致的瞭解,就可以使用該資訊儘可能地選擇開銷小的操作。在許多情況下,更高效的方法將與較慢的方法一樣簡單。例如,當需要儲存使用鍵值查詢的大量物件時,可以使用雜湊表或有序對映(ordered map)。兩者都通常在庫包中提供,並且都簡單易用。但是,雜湊表可以輕鬆地快 5 到 10 倍。因此,除非需要對映(map)提供有序屬性,否則你應使用雜湊表。
作為另一個示例,請考慮使用諸如 C 或 C++ 之類的語言分配的結構陣列。有兩種方法可以執行此操作。一種方法是讓陣列儲存指向結構的指標,在這種情況下,你必須首先為陣列分配空間,然後為每個單獨的結構分配空間。而直接將結構儲存在陣列中效率要高得多,因此你只需為所有內容分配一大塊記憶體。
如果提高效率的唯一方法是增加複雜性,那麼選擇就更困難了。如果更高效的設計僅增加了少量複雜性,並且複雜性是隱藏的,也就是說它不影響任何介面,那麼它可能是值得的(但要注意:複雜性是增量產生的)。如果更快的設計增加了很多實現複雜性,或者導致了更複雜的介面,那麼最好還是從更簡單的方法開始,並在效能開始成為問題時再進行最佳化。但是,如果你有明確的證據表明效能在特定情況下很重要,那麼你不妨立即實現更高效的方法。
在 RAMCloud 專案中,我們的總體目標之一是為透過資料中心網路訪問儲存系統的客戶端機器提供儘可能低的延遲。結果,我們決定使用特殊的硬體進行聯網,從而使 RAMCloud 繞過核心並直接透過網路介面控制器傳送和接收資料包。儘管增加了複雜性,但我們還是做出了這個決定,因為我們從先前的測量中知道,基於核心的網路太慢了,無法滿足我們的需求。在 RAMCloud 系統的其餘部分,我們能夠進行簡單設計。把這個大問題“正確解決”會讓其他事情變得更加容易。
通常來說,簡單的程式碼往往比複雜的程式碼執行得更快。如果你已經透過定義規避了特殊情況和異常情況,那麼就不需要程式碼來檢查這些情況,系統就會執行速度更快。深類比淺類更高效,因為它們為每個方法呼叫完成了更多工作。淺類會導致更多的層級交叉,並且每個層級交叉都會增加執行開銷。
20.2 修改前(和修改後)的測量
但是假設你的系統仍然太慢,即使你已經按照上面描述的方式設計了它。根據你對什麼導致了效能問題的直覺,很容易匆忙進行效能調整。不要這樣做!程式設計師對效能的直覺是不可靠的。即使對於有經驗的開發人員也是如此。如果你開始根據直覺進行修改,你會把時間浪費在實際上無法提高效能的事情上,並且在這個過程中可能會使系統變得更加複雜。
進行任何更改之前,請測量系統的現有行為。這有兩個目的。首先,這些測量將找到效能調整能產生最大影響的地方。僅僅測量頂層的系統性能是不夠的,這可能會告訴你係統速度太慢,但不會告訴你原因。你需要進行更深入的測量,以詳細確定影響整體效能的因素。目標是找到系統中當前花費了大量時間的、少量非常具體的、以及你有改進想法的地方。測量的第二個目的是提供基線,以便你可以在進行更改後重新測量效能,以確保效能確實得到改善。如果更改並未在效能上產生可測量的差異,則將它們撤銷(除非它們使系統更簡單)。保留複雜性是沒有意義的,除非它提供了顯著的速度提升。
20.3 圍繞關鍵路徑進行設計
到這一步,假設你已經仔細分析了效能並確定了一段速度緩慢到足以影響整個系統的效能的程式碼。改善其效能的最佳方法是進行“根本性的”更改,例如引入快取,或使用其他演算法(例如,平衡樹還是列表)。我們決定繞過核心進行 RAMCloud 中的網路通訊的決定是一個根本性修正的示例。如果你找到了一個根本性的修正,則可以使用前面各章中討論的設計技術來實現它。
不幸的是,有時會出現一些沒有根本解決辦法的情況。這就把我們帶到本章的核心問題,即如何重新設計現有程式碼,使其執行更快。這應該是你不得已才採取的方法,並且不應該經常發生,但是在某些情況下它可能會帶來很大的不同。關鍵思想是圍繞關鍵路徑設計程式碼。
首先,問你自己在通常情況下執行所需任務必須執行的最少程式碼量是多少。忽略任何現有的程式碼結構。想象一下你正在編寫一個僅實現關鍵路徑的新方法,這是在最常見的情況下必須執行的最少程式碼量。當前的程式碼可能充滿特殊情況,但在此練習中,請忽略它們。當前的程式碼可能會在關鍵路徑上涉及多個方法呼叫,想象一下你可以將所有相關程式碼放在一個方法中。當前程式碼可能還使用了各種變數和資料結構,請只考慮關鍵路徑所需的資料,並假定一些最適合關鍵路徑的資料結構。例如,將多個變數合併為一個值可能是有意義的。假設你可以完全重新設計系統,以最大程度地減少執行關鍵路徑所必須包含的程式碼。我們把這段程式碼稱為“理想的程式碼”。
理想的程式碼可能會與你現有的類結構衝突,並且可能不切實際,但它提供了一個很好的目標:這代表了可能是最簡單和最快的程式碼。下一步是尋找一種新設計,使其儘可能接近理想狀態,同時又要保持整潔的結構。你可以應用本書前面各章中的所有設計思想,但要保持(大部分)理想程式碼的完整性。你可能需要在理想程式碼上新增一些額外的程式碼,以便實現整潔的抽象。例如,如果程式碼涉及雜湊表查詢,引入一個額外的方法呼叫到一個通用的雜湊表類是可以的。根據我的經驗,幾乎總是能找到一種簡潔明瞭但是又非常接近理想狀態的設計。
在此過程中發生的最重要的事情之一是從關鍵路徑中移除特殊情況。當代碼執行緩慢時,通常是因為它必須處理各種不同的情況,並且程式碼的結構也是為簡化所有不同情況的處理而設計的。每個特殊情況都以額外的條件語句和/或方法呼叫的形式向關鍵路徑添加了一些程式碼。每一個這種新增都會使程式碼變慢。重新設計效能時,請嘗試減少必須檢查的特殊情況的數量。理想情況下,開頭應該有一個 if 語句,該語句可以透過一個測試檢測所有特殊情況。在正常情況下,只需要進行這一項測試,之後就可以執行關鍵路徑,而無需對於特殊情況進行其他測試。如果初始測試失敗(這意味著發生了特殊情況),則程式碼可以分叉到關鍵路徑之外的位置以進行處理。對於特殊情況來說,效能並不是那麼重要,因此你可以將特殊情況下的程式碼設計得更簡單而不用太追求效能。
20.4 示例:RAMCloud 緩衝區
讓我們考慮一個例子,在這個例子中對 RAMCloud 儲存系統的 Buffer 類進行了最佳化,在最常見的操作中實現了約兩倍的效能提升。
RAMCloud 使用 Buffer 物件管理可變長度的記憶體陣列,例如遠端過程呼叫的請求和響應訊息。Buffer 的設計旨在減少記憶體複製和動態儲存分配的開銷。Buffer 中看上去儲存的是一個線性的位元組陣列,但為了提高效率,它允許底層儲存將其劃分為多個不連續的記憶體塊,如圖 20.1 所示。Buffer 是透過追加資料塊建立的。每個塊要麼是外部的,要麼是內部的。如果塊是外部的,則其儲存空間由呼叫方擁有,Buffer 中儲存對此儲存的引用。外部塊通常用於大型塊,以避免記憶體複製。如果塊是內部的,則 Buffer 擁有該塊的儲存,呼叫者提供的資料將被複制到 Buffer 的內部儲存中。
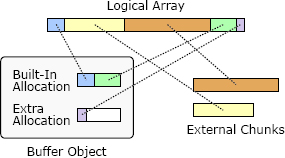
圖 20.1:Buffer 物件使用記憶體塊的集合來儲存線性位元組陣列。內部塊為 Buffer 擁有,並在 Buffer 銷燬時釋放;外部塊不為 Buffer 所有。
每個 Buffer 內建一個小的分配器,這是一個可用於儲存內部塊的記憶體塊。如果此空間已用完,則 Buffer 需要額外分配記憶體,這些分配的記憶體必須在 Buffer 銷燬時進行釋放。內部塊對於小塊來說是很方便的,因為其記憶體複製的成本可以忽略不計。圖 20.1 顯示了一個具有 5 個塊的 Buffer:第一個塊是內部的,接下來的兩個塊是外部的,最後兩個塊是內部的。
Buffer 類本身代表一個“根本性的修復”,因為它消除了開銷大的記憶體複製,而如果沒有它的話,就需要進行複製。例如,在 RAMCloud 儲存系統中組裝包含短標頭和大的物件內容的響應訊息時,RAMCloud 使用帶有兩個塊的 Buffer。第一個塊是包含標頭的內部塊;第二個塊是一個外部塊,它引用 RAMCloud 儲存系統中的物件內容。這樣就可以在不復制大物件的情況下將響應收集到 Buffer 中。
除了允許不連續塊的基本設計外,在最初的實現中,我們並沒有嘗試最佳化 Buffer 類的程式碼。然而,隨著時間的流逝,我們注意到 Buffer 越來越多地被使用。例如,在執行每個遠端過程呼叫的期間,至少會建立四個 Buffer 物件。最終,我們發現最佳化 Buffer 的實現可能會對整體系統效能產生顯著影響。我們決定看看是否可以提高 Buffer 類的效能。
Buffer 最常見的操作是使用內部塊為少量新資料分配空間。例如,在為請求和響應訊息建立標頭時就會發生這種情況。我們決定使用將此操作作為最佳化的關鍵路徑。在最簡單的情況下,可以透過擴大 Buffer 中最後一個現有塊來分配空間。但是,只有在最後一個現有塊是內部塊,並且在其分配中仍有足夠的空間來容納新資料時才有可能。理想的程式碼將執行一次檢查,以確認簡單方法是否可行,然後將調整現有塊的大小。
圖 20.2 展示了關鍵路徑的原始程式碼,該程式碼以 Buffer::alloc 方法開頭。在最快的使用場景下,Buffer::alloc 呼叫 Buffer::allocateAppend,後者再呼叫 Buffer::Allocation::allocateAppend。從效能的角度來看,此程式碼有兩個問題。第一個問題是要單獨檢查多個特殊情況,並且有些還是重複的。首先,Buffer::allocateAppend 檢查了 Buffer 當前是否有任何分配。然後程式碼檢查了兩次以檢視當前分配是否有足夠的空間容納新資料:一次在 Buffer::Allocation::allocateAppend 中,一次在其返回值被 Buffer::allocateAppend 測試時。此外,該程式碼沒有嘗試直接擴充套件最後一個塊,而是在不考慮最後一個塊的情況下分配了新空間。然後,Buffer::alloc 檢查該空間是否恰好與最後一塊相鄰,在這種情況下,它將新空間與現有塊合併,這也導致了額外的檢查。總體而言,該程式碼在關鍵路徑上測試了 6 個不同的條件。
char* Buffer::alloc(int numBytes)
{
char* data = allocateAppend(numBytes);
Buffer::Chunk* lastChunk = this->chunksTail;
if ((lastChunk != NULL && lastChunk->isInternal()) &&
(data - lastChunk->length == lastChunk->data)) {
// Fast path: grow the existing Chunk.
lastChunk->length += numBytes;
this->totalLength += numBytes;
} else {
// Creates a new Chunk out of the allocated data.
append(data, numBytes);
}
return data;
}
// Allocates new space at the end of the Buffer; uses space at the end
// of the last current allocation, if possible; otherwise creates a
// new allocation. Returns a pointer to the new space.
char* Buffer::allocateAppend(int size) {
void* data;
if (this->allocations != NULL) {
data = this->allocations->allocateAppend(size);
if (data != NULL) {
// Fast path
return data;
}
}
data = newAllocation(0, size)->allocateAppend(size);
assert(data != NULL);
return data;
}
// Tries to allocate space at the end of an existing allocation. Returns
// a pointer to the new space, or NULL if not enough room.
char* Buffer::Allocation::allocateAppend(int size) {
if ((this->chunkTop - this->appendTop) < size)
return NULL;
char *retVal = &data[this->appendTop];
this->appendTop += size;
return retVal;
}
圖 20.2:使用內部塊在 Buffer 的末尾分配新空間的原始程式碼。
原始程式碼的第二個問題是它的層級太多,而且都很淺。這既是效能問題,也是設計問題。除了對 Buffer::alloc 的原始呼叫之外,關鍵路徑還進行了兩個額外的方法呼叫。每個方法呼叫都需要額外的時間,其中一個呼叫的結果必須由其呼叫者檢查,這導致了額外的需要考慮的特殊情況。第 7 章討論了當你從一個層級轉到另一個層級時,抽象通常應該如何變化,但是圖 20.2 中的所有三個方法都具有相同的簽名,它們提供了基本相同的抽象。這是一個危險訊號。Buffer::allocateAppend 幾乎是一個透傳方法,它的唯一作用是在需要時建立新的分配。額外的層級使程式碼更慢,也更複雜。
為了解決這些問題,我們重構了 Buffer 類,使其設計圍繞效能最關鍵的路徑進行。我們不僅考慮了上面的分配程式碼,還考慮了其他幾個常見的執行路徑,例如檢索當前儲存在 Buffer 中的資料的總位元組數。對於這些關鍵路徑中的每一個,我們試圖確定在通常情況下必須執行的最少程式碼量。然後,我們圍繞這些關鍵路徑設計了類的其餘部分。我們還應用了本書中的設計原則來簡化整個類。例如,我們消除了淺的層並建立了更深的內部抽象,還減少了需要檢查的特殊情況數量。重構後的類比原始版本小 20%(1476 行程式碼,而原始版本為 1886 行)。
圖 20.3 展示了在 Buffer 的內部塊中分配空間的新關鍵路徑。新程式碼不僅更快,而且更容易閱讀,因為它避免了淺抽象。整個路徑使用單個方法來處理,它使用單個測試來排除所有特殊情況。新程式碼引入了新的例項變數 availableAppendBytes 以簡化關鍵路徑,該變數跟蹤緩衝區中最後一個塊之後有多少空間直接可用。如果沒有可用空間,或者 Buffer 中的最後一個塊不是內部塊,或者 Buffer 根本不包含任何塊,則 availableAppendBytes 為零。只需要對 availableAppendBytes 進行測試,即可一次性檢查三個不同的特殊情況。圖 20.3 中展示的就是處理還有可用空間這種常見情況的最少量程式碼。
char* Buffer::alloc(int numBytes) {
if (this->availableAppendBytes >= numBytes) {
// There is extra space just after the current
// last chunk, so we can allocate the new
// region there.
Buffer::Chunk* chunk = this->lastChunk;
char* result = chunk->data + chunk->length;
chunk->length += numBytes;
this->availableAppendBytes -= numBytes;
this->totalLength += numBytes;
return result;
}
// We're going to have to create a new chunk.
}
圖 20.3:用於在 Buffer 的內部塊中分配新空間的新程式碼。
注意:可以透過在需要時重新計算各個塊的總緩衝區長度來消除對 totalLength 的更新。但是,這種方法對於具有許多塊的大型 Buffer 而言將是效能開銷大的,並且獲取 Buffer 的總長度是另一種常見的操作。因此,我們選擇向 alloc 新增少量額外開銷,以確保 Buffer 長度始終立即可用。
新程式碼的速度約為舊程式碼的兩倍:使用內部儲存將 1 位元組字串附加到 Buffer 的總時間從 8.8 納秒降低到了 4.75 納秒。許多其他 Buffer 操作也因為這次修改而加快了速度。例如,構建一個新的 Buffer 並在內部儲存中追加一小塊、然後再銷燬 Buffer 的時間從 24 納秒降到了 12 納秒。
20.5 結論
本章總體上最重要的經驗是,簡潔的設計和高效能是可以相容的。重寫 Buffer 類可將其效能提高兩倍,同時簡化了其設計並將程式碼量減少了 20%。複雜的程式碼通常會很慢,因為它會執行無關或冗餘的工作。另一方面,如果你編寫整潔、簡單的程式碼,則系統可能會足夠快到你從一開始就不必擔心效能。在少數需要最佳化效能的情況下,關鍵還是簡化:找到對效能最重要的關鍵路徑,並使它們儘可能簡單。